近日,中国海洋大学信息科学与工程学部电子工程学院李光亮课题组在人工智能、机器人领域的论文“Transferring Policy of Deep Reinforcement Learning from Simulation to Reality for Robotics”被国际顶级学术期刊Nature子刊《Nature Machine Intelligence》录用发表。《Nature Machine Intelligence》关注人工智能、机器学习和机器人领域具有重要影响的科研成果,评审标准严格,每年发表长论文约100篇。
智能性与自主性是当今世界机器人研究的科技前沿、热点和难点问题。作为新兴的人工智能方法,深度强化学习模仿人类试错学习机制,允许智能体通过与外部环境交互及试错的经历进行自主学习以优化控制策略,进而提高机器人的智能性和自主性。近年来,深度强化学习在许多领域取得了巨大成功,在机器人自主控制领域也显示出巨大潜力。尽管如此,一方面,深度强化学习等人工智能技术可能给机器人带来风险、失控甚至危害;另一方面,机器人的学习效率和安全性问题成为深度强化学习应用于实体机器人控制的瓶颈。针对以上问题,课题组创新性地提出让人参与到机器人的自主学习过程中,以提高机器人的学习效率和控制系统置信度,并分别在社交服务机器人Haru(由课题组与日本本田技术研究所、麻省理工学院以及帝国理工学院等研究人员成立的社交智能机器人联盟Socially Intelligent Robotics Consortium联合研发)、单自主式水下航行器(AUV)和多AUV编队控制成功应用。相关研究成果被国际机器人与智能体顶级学术会议ICRA(2021)、IROS(2022,2021)、AAMAS(2021)和国际海洋工程顶尖学术期刊《Ocean Engineering》 (2022a,2022b,2021)、国际智能体与多智能体顶尖期刊《Journal of AAMAS》(2020)录用发表。其中,ICRA、IROS是全球规模最大、最具影响力的机器人顶级会议,《Ocean Engineering》是海洋工程领域顶级学术期刊。
引入人的监督和反馈虽然可以大幅度提高机器人的学习效率,但由于动作执行时间较长导致实体机器人学习控制策略仍需要较长的时间并可能引发安全性问题。受动物和人类大脑迁移学习机制的启发,课题组深入研究从仿真到现实迁移强化学习方法,提出通过充分利用仿真数据进一步提高机器人学习效率和降低实体机器人执行控制策略时的危险性。课题组在《Nature Machine Intelligence》刊发的论文对从仿真到现实迁移强化学习方法的最新进展以及常用方法原理、应用背景和发展现状进行深入对比分析,并提出将系统识别、逆强化学习、交互强化学习、鲁棒强化学习、离线和离线到在线强化学习等方法的思想应用于从仿真到现实迁移强化学习领域,以研究更高效的迁移强化学习方法,对加快深度强化学习在智能机器人控制领域落地具有重要的现实意义。例如,为了解决虚拟环境和现实环境观测状态或动态模型不匹配的问题,域随机化通过在视觉图像和动态参数中随机添加偏差和噪声为机器人控制策略训练提供丰富经验,以实现虚拟策略到现实环境的一次性迁移(图1)。
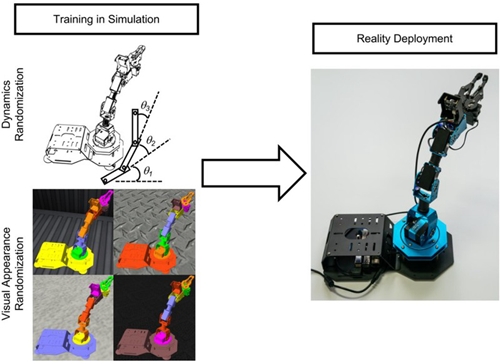
图1 域随机化的原理和应用
李光亮副教授为论文唯一通讯作者,硕士研究生巨浩和隽荣顺为共同第一作者,中国海洋大学为第一作者单位和通讯作者单位。李光亮课题组专注于深度强化学习及其在机器人应用领域的研究,近年来在人在回路强化学习、仿真到现实迁移强化学习、多智能体强化学习等领域取得了系列研究成果,对国内外相关领域研究产生了重要影响。相关研究工作获得国家自然科学基金、山东省自然科学基金与
 高招云直播
高招云直播






