 高招云直播
高招云直播

了解腾讯营销
腾讯营销(原腾讯广告)是腾讯面向企业的统一商业服务平台,依托腾讯技术实力与全域生态,整合微信、QQ等海量用户场景,构建超十亿用户流量矩阵,连接用户与品牌,并为广告主提供全经营链路数字化营销解决方案,帮助广告主实现数字化经营与生意增长。
这里有
技术:毫秒级处理海量广告请求,算法、大模型、强化学习、AIGC创意生成,工业级难题,真实上线,跑在十亿用户面前;
产品:定义广告主的经营工具,从0到1设计影响真实商业决策的产品体验,每个方案都直接关联真实生意;
营销:用数据和创意重新发明增长,在大规模的商业场景里验证每一个想法。
期待与你一起,探索AI时代下,技术与商业的最新可能。

广告技术团队多岗位热招中
点击下方岗位名称,一键投递!
青云热招课题
广告推荐模型 Scaling Up(序列和非序列统一建模方向)
面向生成式推荐的强化学习优化技术研究
面向商业化推荐平台的生成式推荐技术研究
基于大模型Agent的腾讯电商广告推荐研究
多模态大模型与强化学习驱动的广告投放Agent
面向商业化推荐的统一多模态生成
面向商业化场景的统一多模态表征大模型技术研究
基于LLM的广告系统实验设计与衡量
机器学习平台技术研究
优化算法在广告推荐场景的应用研究
基于Agentic AI的自主进化广告审核专家Agent构建
大规模语义理解的 agent 数据和知识问答

技术校招岗位
算法-多模态方向
算法-推荐算法方向
算法-机器学习方向
技术研究-高性能计算方向
算法-数据科学方向

技术社招岗位
大模型深度LTV-算法工程师
大模型广告算法工程师-搜索广告方向
高级广告算法工程师-海外联盟方向
多模态大模型算法工程师
大模型推荐算法负责人

摘要
推荐系统在历史上一直沿着两个基本独立的范式发展:用于对多领域类别特征之间的相关性进行建模的特征交互模型,以及用于从历史交互序列中捕捉用户行为动态的序列模型。尽管近期的趋势试图在共享的主干网络中桥接这两种范式,但我们在实验中发现,将这两个分支进行简单的统一可能会导致一种我们称之为序列坍塌传播(Sequential Collapse Propagation, SCP)的问题。当序列特征与维度表征处于低纬的异构非序列特征进行交互时会导致序列特征的维度发生坍塌 。
为了克服这一挑战,我们提出了 TokenFormer。首先,我们引入了一种“底层全量-顶层滑动”(Bottom-Full-Top-Sliding, BFTS)注意力机制,该机制在底层网络应用全时序自注意力,而在顶层网络应用窗口大小逐层收缩的滑动注意力。其次,我们引入了一种“非线性交互方式”(Non-Linear Interaction Representation, NLIR),对隐式表征应用单侧的非线性乘法变换。在公开基准测试和腾讯广告平台上的大量实验证明了其业界领先的最佳性能,同时也证实了 TokenFormer 在统一建模下显著提升了维度的鲁棒性与表征的判别力。
本文工作已发表至arXiv,论文题目《TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds》。点击查看原文:TokenFormer:统一多领域与序列推荐世界。01
引言
现代工业级推荐系统早已不再局限于单一的建模范式。真实的业务场景要求模型必须能够同时对静态的异构多领域特征,以及用户动态的序列历史行为,进行全局的综合推理。
尽管走向“大一统”建模是大势所趋,但如何真正跨越这两大技术分支的鸿沟,至今仍是业界的一大难题。传统的做法往往是通过异构子网络、专家模块(experts)或后期融合(late-fusion)机制将它们组合在一起。尽管近期 InterFormer、OneTrans、HyFormer 和 Kunlun 等尝试向统一架构迈进的前沿工作,但它们往往在内部依然通过混合堆叠或交替组件的方式,保留着各分支中的模块解耦。
因此,迄今为止业界依然缺乏一个真正“完全融合”的底层架构,能够在一个单一且一致的计算范式内,原生并优雅地完成“field-field”、“sequence-sequence”以及“sequence-field”的交互建模。
工业级推荐系统的核心挑战在于如何同时处理极度稀疏的异构静态 Field 特征与用户动态的历史行为特征 Sequence。尽管业界正试图将“非序列多域特征”与“用户兴趣序列”融合,但统一架构面临着一个未被充分探讨的障碍:我们称之为序列坍塌传播效应 (Sequential Collapse Propagation, SCP) 。由于非序列特征往往信息稀疏且容易陷入低维子空间,它们在统一框架模块中会“污染”并压垮序列特征的维度 。TokenFormer 的提出则是为解决这类问题。
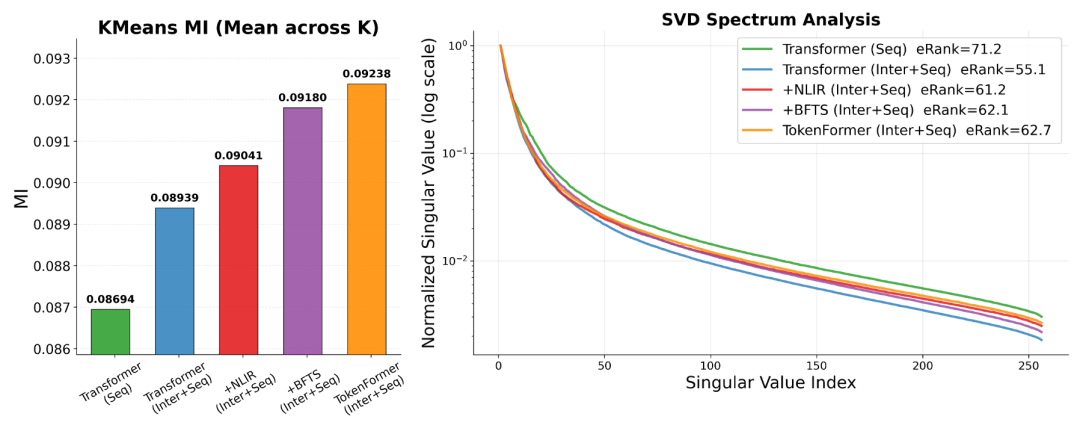
图1-1 TokenFormer 在判别力与维度鲁棒性上的消融对比
如图1-1的实验分析所示:左图:由互信息(MI)衡量的表征判别力(Discriminability)。右图:由奇异值谱与有效秩衡量的维度鲁棒性(Dimensional Robustness)。
与纯序列的 Transformer(绿色曲线)相比,使用标准 Transformer 将序列与非序列特征进行简单粗暴的联合建模(蓝色曲线),虽然能提升表征的判别力,但也会导致序列表征出现极其陡峭的谱衰减以及更低的有效秩,这直观地印证了“序列坍塌传播 (Sequential Collapse Propagation)”的现象。
而本文提出的 BFTS 与 NLIR 机制有效地遏制了这种坍塌,在成功恢复维度鲁棒性的同时,进一步拔高了模型的表征判别力。
为了打破这一困境,我们推出了TokenFormer。该架构通过三大核心设计,从根本上重塑了统一建模:
彻底统一的输入流:打破不同特征的边界,将静态稀疏非序列特征(Non-Sequential Static Fields Feature)、行为序列(Senquential Features Tokens)以及待推荐候选目标属性 (Target Attributes),全部汇聚成一条单一的、同构的 Token 流。这使得所有的依赖关系都能在统一的网络块中进行学习。
BFTS 层次化注意力机制:我们引入了“底层全量-顶层滑动”(Bottom-Full-Top-Sliding, BFTS)注意力方式:在网络浅层执行全量时序自注意力来建立全局视角,而在深层则采用窗口不断收缩的滑动窗口注意力(SWA)来聚焦局部时序特征已经预测。
NLIR 非线性门控机制:我们在模型表征层加入了“非线性交互表示”(Non-Linear Interaction Representation, NLIR),一种单侧的非线性乘法变换机制,来增强网络的非线性能力加强表征的判别性。
正如前文图 1-1 所示,BFTS 与 NLIR 的结合,有效地保护并恢复了表征的内在维度。这不仅增强了特征的判别力,更大副减轻了由于静态特征“维度问题”对序列建模造成的破坏。我们将在实验部分提供详尽的分析来验证这些发现。
我们在公开数据集以及腾讯大规模在线广告平台上的大量实验,充分证明了 TokenFormer 的效果。除了在线下和线上核心指标的全面提升外,我们还对注意力模式、维度鲁棒性以及表征判别力进行了深度剖析。结果表明,这种全新的架构不仅显著提高了推荐精度,更有力地遏制了因序列与非序列 Token 统一建模而引发的维度坍塌问题。
02
问题设定与预备知识
TokenFormer 将推荐抽象为在
一个强大的统一主干网络(Backbone),应当能够对集合
:非序列的用户、物品及上下文特征之间的关联,这正是传统“特征交互模型”的核心处理对象。 :用户历史行为轨迹之间的关联,对应于序列推荐中的自注意力(Self-attention)机制。 :目标侧(Target-side)各特征之间的关联,用于构建表达能力强大的目标物品表征。 :历史行为与当前目标之间的相关性,对应于目标感知推荐(如 DIN)中的目标注意力(Target-attention)机制。 :非序列的用户/上下文特征与用户动态行为之间的依赖关系,这通常在交叉特征序列建模中被处理。 :用户/上下文与目标物品之间的匹配关联,这是协同过滤和特征交互模型赖以生存的根基。
因此,真正的统一推荐,呼唤的是一种能够同时且原生支持这六种交互类型的单一计算架构,而不是把特征交互和序列建模生硬地拆分、拼凑成一个异构系统。
03
TokenFormer 核心架构
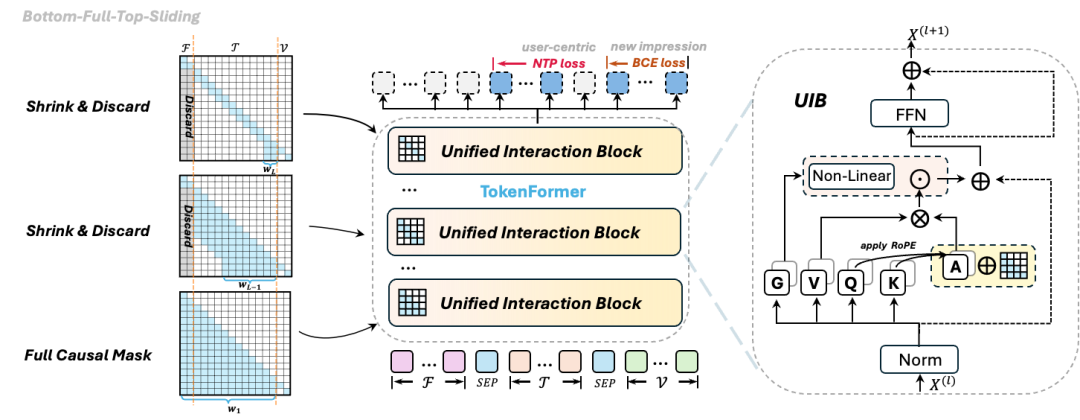
图3-1 TokenFormer 架构全景:从统一输入表示到分层注意力机制
传统的推荐模型通常会针对不同类型的数据设计各种各样的异构模块。与它们不同,我们将所有实体的 Embedding 直接拼接在一起,为模型的第一层构建了一个完全统一的输入表示
以包含了用户具体动作(Action-aware)的场景为例,这个统一的输入序列
值得一提的是,我们彻底抛弃了常规做法中用来区分特征类型的显式Embedding(Type Embeddings)。取而代之的是,我们在整条 Token 流中贯穿使用了统一的旋转位置编码(RoPE)来注入相对位置信息。这种精妙的设计使得模型能够在一个真正统一的几何空间内,精准捕捉各类特征之间的深层依赖关系(详情参见后续相关章节)。
此外,为了让模型清楚地感知不同特征组的划分,我们采用了一种极简的做法:在各个特征片段之间插入一个特殊的分隔符Token
一、统一交互块
TokenFormer 采用了一个同构的、仅包含解码器(decoder-only)的主干网络,其中堆叠了
每一个交互块都可以看作是标准注意力块的一个变体,并且特别通过两项关键创新进行了强化:
“底层全量-顶层滑动”(Bottom-Full-Top-Sliding, BFTS) 注意力机制,它会根据所处的网络层级动态调整注意力掩码(Mask);
非线性交互表示(NLIR)模块,它通过乘法调制来优化注意力的输出。第
层的核心计算过程可以概括如下: 这里,
代表使用了我们提出的 BFTS 掩码策略( )的注意力机制,而 则是指对注意力输出执行的非线性交互操作。这两个组件的详细公式将分别在后续章节中给出。
通过堆叠这些交互块,TokenFormer 在浅层渐进式地整合全局的上下文信息,而在深层则更加强调局部的时序结构,同时,它还借助非线性交互机制不断提升注意力输出的表达能力。
二、BFTS Attention Mechanism
对于第
其中
滑动窗口注意力(Sliding Window Attention, SWA)
面对超长的用户行为序列,降低稠密注意力计算开销最直观的办法,就是将每个 Token 的注意力限制在一个局部的“感受野”内。具体而言,在 SWA 机制下,Token
与全量因果注意力相比,SWA 将有效的注意力范围从整个历史前缀缩小到了一个局部窗口,从而迫使模型更加专注地捕捉近期的时序依赖关系。
在统一推荐建模中,SWA 显得尤为契合,原因有二:首先,它将注意力机制从稠密的全局交互降维成了稀疏的局部交互,大幅削减了计算量和显存开销,这对于包含超长用户历史的统一 Token 序列至关重要。其次,在推荐场景中,许多细粒度的行为依赖本质上都是局部的,例如短期兴趣的延续以及相邻行为的共现。通过将注意力约束在一个滑动窗口内,模型能够强化对这些局部时序模式的捕捉,同时过滤掉久远且可能带有噪声的冗余行为干扰。
从统一 SWA 到“底层全量-顶层滑动”(Bottom-Full-Top-Sliding, BFTS)
尽管 SWA 优势明显,但在统一架构的所有网络层中无差别地生搬硬套 SWA 却是次优的选择。在 TokenFormer 中,输入序列不仅包含动态的行为 Token,还混合了大量的异构静态特征 Token。因此,在网络的浅层,模型必须具备足够宽广的感受野,以便在这些异构 Token 之间建立全局的跨域交互。如果从一开始就把所有网络层都限制在局部窗口内,模型会过早地丧失在整条统一序列中传递全局上下文信息的能力。
为了在“全局交互”与“局部提纯”之间找到最佳平衡点,我们精心设计了 “底层全量-顶层滑动”(BFTS)机制。其核心理念非常清晰:浅层网络采用全量因果注意力,在整条统一 Token 流上构建起全面、深度的跨域交互;而在建立好这层全局认知基础之后,深层网络则果断切换为窗口不断收缩的滑动注意力,专门负责提纯局部的时序结构。
这种机制让注意力范围与模型每层输出表征进行深度绑定:底层重在宽广的全局交叉已经融合,顶层精于局部的时序精细化推演。
用数学语言严谨地表述:假设我们有其中
这种窗口尺寸的渐进式收缩,像漏斗一样强制模型将宽泛的全局依赖一步步“蒸馏”成越来越细粒度、越来越局部的精准表征。TokenFormer 将全局上下文建模保留在了最需要它的浅层地基中,只有在模型已经建立起足够丰富的跨 Token 交互之后,才在深层果断引入局部稀疏化。
三、非线性交互表示(Non-Linear Interacted Representation, NLIR)
TokenFormer 融入了一种统一的非线性交互范式,其核心目的在于提升特征的表征判别力(representational discriminability)并恢复维度鲁棒性(dimensional robustness)。
与传统的门控机制仅仅将调制分支视为一个被动的缩放系数不同,我们将其视为一种经过学习的非线性变换,它与主特征流进行的是实质性的乘法交互。这种设计不仅是为了强化特征的表达能力,更是为了强力遏制表征坍塌。
为了有效调节密集的用户行为信号与稀疏的静态多领域特征之间的依赖关系,我们在注意力层的输出
然后,利用这个门控信号对注意力输出进行调制:
其中
四、SwiGLU 前馈网络
在完成门控注意力操作之后,TokenFormer 采用了一个基于 SwiGLU 的前馈网络。给定前面得到的交互表征
其中
五、统一的优化目标
TokenFormer 的一大架构优势在于:完全相同的 Token 架构,能够在共享的监督框架下,无缝兼容不同的推荐训练范式。 具体而言,我们支持以下两种主流设定:
User-Centric Setting
该模式采用类似大模型的 Next-Token 密集自回归监督。历史行为、静态用户画像以及候选物品被放在一起联合建模,监督信号贯穿整条序列。这种训练方式能够倒逼模型从完整的交互上下文中,学习到极其全面、深度的用户表征。
New Impression Only Setting
该模式高度契合工业界真实的在线精排场景。用户的历史交互记录仅作为“上下文先验”提供背景信息(不参与 Loss 的梯度回传)。模型将所有的算力与优化目标(Loss)全部聚焦于当前最新曝光的候选物品上。
统一的损失函数
无论采用上述哪种范式,在数学上都可以统一表达。假设
对于每一个需要预测的索引
04
实验
实验数据集 (Datasets)
为了全面评估 TokenFormer 的性能与落地潜力,我们在两类截然不同的数据环境下进行了严格测试:
公开基准测试 (KuaiRand-27K):采用序列推荐领域的经典开源数据集,包含约 2.7 万条完整的用户交互轨迹(按 1.9万/2千/5千 的比例严格划分为训练/验证/测试集)。
工业级生产环境 (腾讯营销):为了检验模型在真实高并发业务中的扩展性与泛化能力,我们在腾讯营销平台的多个核心场景中进行了验证。与公开数据集不同,这里的交互日志规模高达数十亿级,面临着极其严苛的特征稀疏性与高度动态的用户意图挑战。
一、整体性能评估
为了验证 TokenFormer 的真实战力,我们与当前业内众多顶尖(SOTA)模型进行了正面交锋。根据训练目标的不同,我们将这些模型划分为两部分进行实验,结果如表4-1所示:
User-Centric:这类模型(如 HSTU、HSTU-Ultra)采用 Next-Token 预测目标,对完整的用户历史轨迹进行自回归训练。它的优势是能完美捕捉用户行为的逐步演进,代价则是训练时存在一定的计算冗余。
New Impression Only:专为预测最新曝光的候选物品而生(如 OneTrans、HyFormer)。在这里,冗长的历史行为仅仅被当做“上下文背景”,模型不再计算历史轨迹的预测 Loss。这种设定与工业界真实的精排场景高度一致。
在 KuaiRand-27K 数据集上的实验结果主要得出以下三点结论:
在User-Centric设定下的性能表现:TokenFormer 在保留完整序列的基线模型中取得了较优的性能。具体而言,参数量较小的 TokenFormer-Tiny 版本在 AUC 指标上较基线 Transformer 提升了 5.00‰,较 HSTU-Ultra 模型提升了 2.05‰。这表明我们的统一架构在结合异构特征与时序依赖方面具有有效性。
时序监督信号的价值:横向对比发现,采用全序列预测(Next-Token 预测)的模型,其整体 AUC 普遍高于仅优化单点目标的模型。这说明在训练中保留用户序列的顺序一致性,能够为表征学习提供更丰富的监督信号。
对不同训练设定的适配性:在New Impression Only的单点目标设定下,TokenFormer 依然取得了具有竞争力的性能表现,表明该架构能够灵活适配不同的推荐优化范式与具体的工业级应用需求。
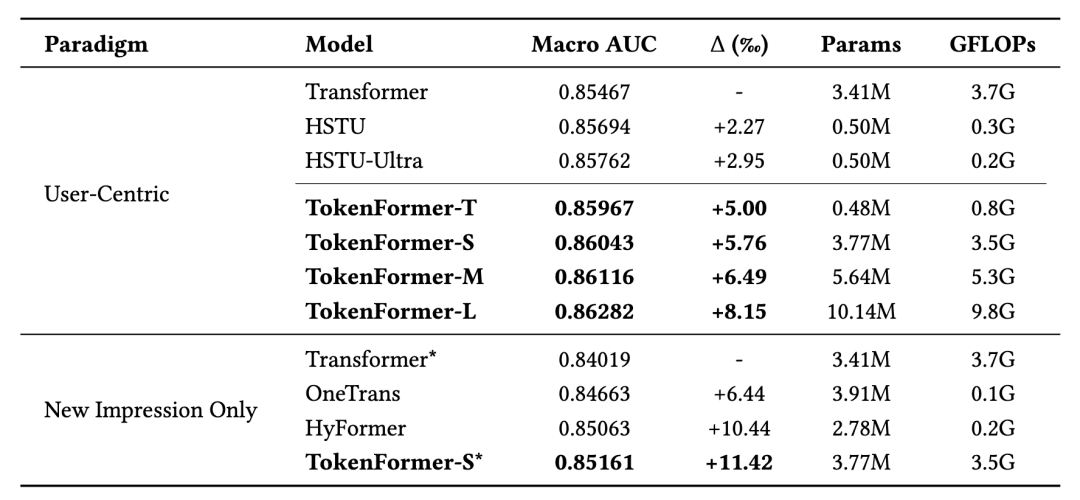
表4-1 模型实验结果
二、NLIR 与 BFTS 对判别力的提升
为了验证 NLIR 模块中“非线性乘法交互”究竟带来了多大的优势,我们引入了 互信息(Mutual Information, MI)来进行严格的量化分析。
由于神经网络输出的表征是高维且连续的,直接计算互信息非常困难。为此,我们使用 K-Means 算法将高维表征空间划分为多个簇(Clusters);然后,计算这些聚类结果与真实目标标签之间的互信息。这个指标成为了衡量模型输出 Embedding 表达能力的直接硬指标。
实验结果(如图4-1所示)清晰地印证了我们两大核心组件的价值:BFTS 与 NLIR 的强强联合,在几乎所有评估 K cluster 数量 下,都带来了互信息(MI)的显著且稳定的提升。
这与我们的理论直觉高度吻合,它们在 TokenFormer 中扮演着相辅相成的角色:
BFTS(层次化注意力):构筑了一种结构化的感受野,有效阻断了不同类型特征之间不必要的交叉干扰。
NLIR(非线性门控):通过显式的乘法交互极大地拓宽了模型的表达上限,负责将复杂的原始信号提炼为高保真的精细表征。
除此之外,数据还揭示了一个不容忽视的真相:单靠 “用户行为序列” 是远远不够的。 实验显示,即便是最基础的 Transformer,只要加入了静态的多领域特征进行联合建模,其判别力也远超纯序列模型。这说明静态属性(如用户画像)提供了不可或缺的“类别先验”,能够有效地作为锚点,稳住用户不断改变的动态兴趣。
然而,简单的联合建模方案并非完美的解法。它在引入静态特征辅助决策的同时,往往会触发“序列坍塌传播 (SCP)”,导致序列特征的高维表达能力大幅衰减。TokenFormer 则通过其创新的架构设计,有效规避了异构特征融合时的这一内生缺陷。
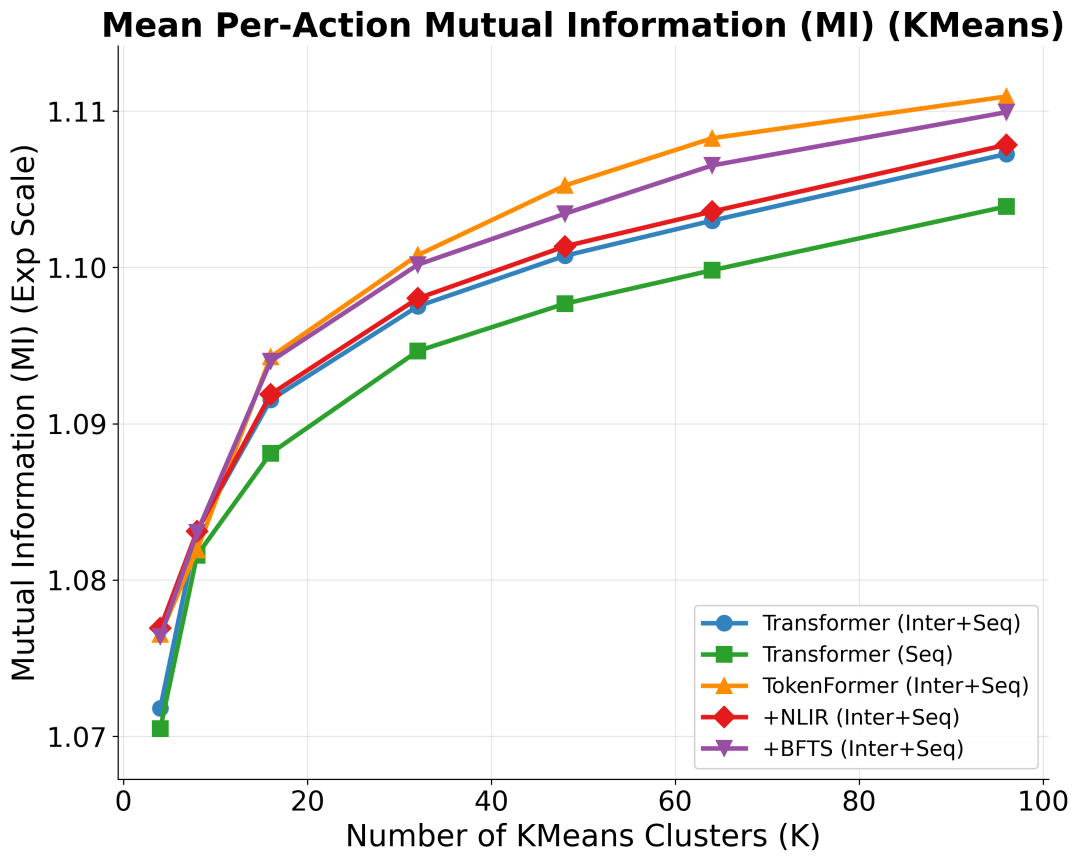
图4-1 不同聚类粒度下的平均互信息(Mean Per-Action MI)消融对比
三、NLIR与BFTS对维度鲁棒性的影响
我们认为,在统一推荐建模中,特征维度的坍塌并非不可避免。具体而言,BFTS 架构与 NLIR 机制能够从不同层面缓解这一问题:BFTS 通过在不同网络层动态调整注意力范围,阻止了低秩(Low-rank)噪声的传播;而 NLIR 则通过对条件不佳的静态特征引入非线性变换,增强了表征的维度鲁棒性。
为了验证这一假设,我们在 KuaiRand-27k 数据集上进行了逐层的谱分析(Spectral Analysis)。我们对比了三种模型变体:
标准 Transformer(基础的联合建模);
仅使用 BFTS(浅层使用全局因果注意力,深层使用收缩窗口的滑动注意力);
仅使用 NLIR(在注意力块中引入非线性交互表示)。
我们采用各个网络块隐藏层表征的有效秩(Effective Rank)作为衡量表征鲁棒性的量化指标。
如图4-2的谱轨迹所示,标准的联合建模(蓝色线)表现出极其陡峭的谱衰减,这证实了低秩静态特征的引入确实会导致序列特征发生严重的维度坍塌。而 BFTS 和 NLIR 均能独立且有效地促进维度的恢复:
BFTS(紫色):通过在深层网络中施加局部注意力的先验约束,限制了坍塌的传播,从而防止低秩的静态噪声稀释高频的序列行为信号。
NLIR(红色):通过引入非线性乘法交互促进特征解耦,有效恢复了表征的秩。该机制确保模型能够捕获高表达能力的表征,而不是退化到少数几个简单的显性特征上,从而保留了特征的细粒度信息。
除了核心架构组件外,图4-2中的谱轨迹还揭示了残差连接(Residual Connections)在系统性调节表征秩方面的几何效应:
注意力残差的恢复作用(Attention-Residual Restoration):注意力操作后的残差连接(即
)能够一致地提升有效秩。这表明,注意力残差分支不仅用于稳定梯度优化,还能主动恢复在纯注意力特征变换过程中流失的维度多样性。 FFN 残差的正则化作用(FFN-Residual Regularization):经过前馈网络(FFN)转换后的残差连接(即
)则倾向于将有效秩拉回至一个中间范围。这表明 FFN 残差分支起到了关键的正则化作用,防止表征偏离上一阶段(注意力阶段)设定的秩分布过远。
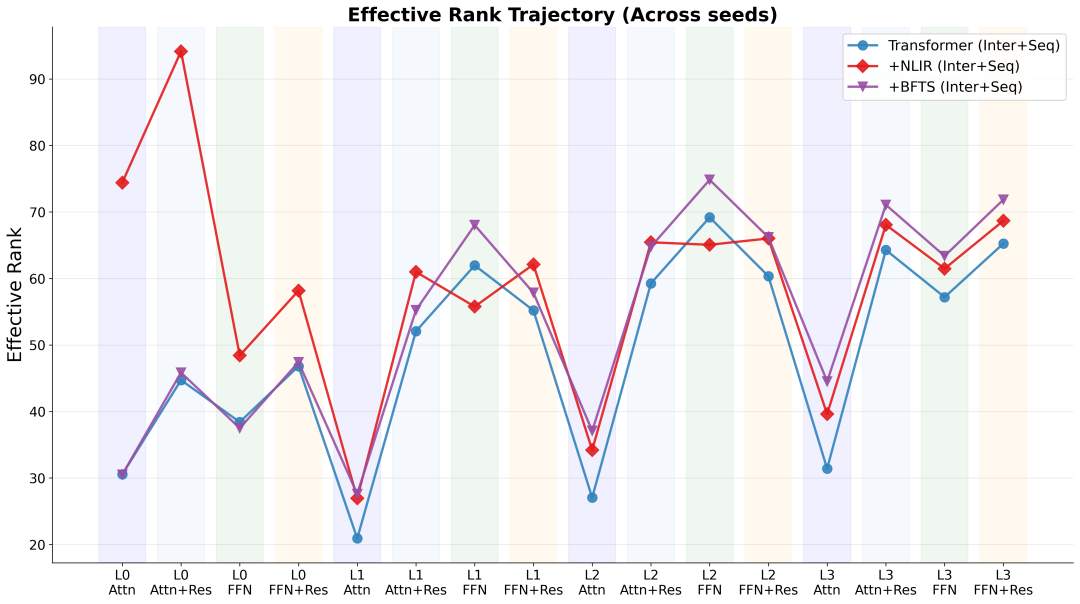
图4-2 跨层 Effective Rank 轨迹(多随机种子平均)
进一步地,我们将分析重点聚焦于序列行为 Token 上,因为它们在统一架构中最容易受到静态特征坍塌传播的波及。如图4-3所示,尽管随着网络深度的增加,有效秩的下降是普遍趋势,但在启用 NLIR 后,这种退化得到了实质性的缓解。相反,标准变体则出现了急剧的下降,表明其序列表征被不断压缩到了低维空间中。
综合上述观察,实验结果与我们的假设高度一致:非线性交互机制在异构 Token 的交互过程中,起到了防止维度坍塌的关键保护作用。这不仅证明了门控机制的价值远超局部的特征筛选,更展现了其在整个网络中维持表征多样性的能力。
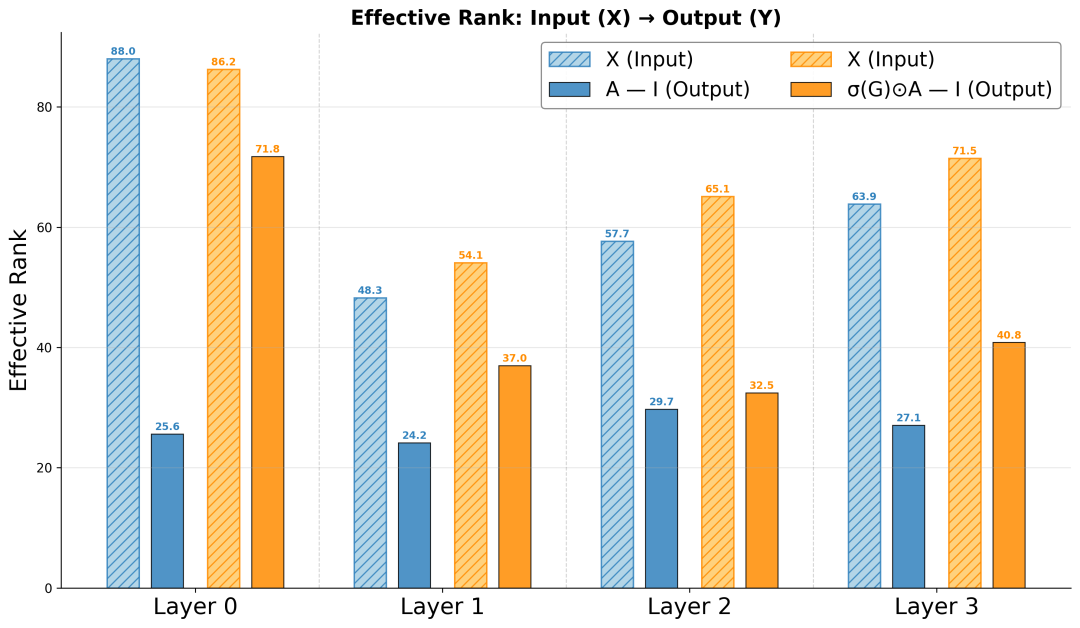
图4-3 序列 Token 逐层 Input→Output eRank 对比
四、BFTS 的逐层注意力行为分析
我们认为,高效的特征交互架构应当为不同的网络层分配特定的注意力感受野。直观而言,模型的学习过程应是一个层层递进的信息提纯流水线:浅层网络应当首先进行全局交互,将低维的静态用户画像与行为序列充分融合;一旦这种全局上下文建立完毕,深层网络就应完全聚焦于局部的时序融合,不再被静态先验信息分散注意力。
为了验证这一点,我们对标准 Transformer 与 TokenFormer 在不同深度的注意力掩码(热力图)及感受野分布(直方图)进行了可视化对比图6所示,发现了两拐模型截然不同的交互行为:
标准 Transformer 的 “注意力漂移”:可视化结果显示,标准模型不仅在浅层关注静态特征,在最深层的网络中,依然会把大量的注意力“回看”到那些遥远的非序列静态位置。直方图数据也印证了这一反直觉的现象:其平均感受野在深层不降反升(从中间层的 40.0 异常扩张至 46.4)。
TokenFormer 的“精细化分工”:相比之下,由于 BFTS 机制的显式约束,TokenFormer 在浅层强制执行了比标准模型更广阔、更充分的跨域交互(平均感受野 52.7 对标 40.0)。而在深层网络中,当引入滑动窗口注意力(SWA)时,它完全切断了对非序列位置的关注。此外,它在收缩的局部窗口内还展现出了极强的“窗口内稀疏性”——模型不会盲目关注局部窗口内的所有 Token ,而是动态地只关注最相关的相邻 Token。
TokenFormer 在预测效果(AUC)上的显著领先,有力地证实了我们的假设:在网络浅层将静态先验与行为序列充分融合后,如果在深层继续反复聚合这些静态信息,不仅是计算上的冗余,还会引入结构性噪声,从而严重稀释模型对高价值时序动态的捕捉能力。
通过利用带状对角线的 SWA 模式屏蔽非序列交互,BFTS 强制收缩了深层的注意力范围,直接丢弃了静态 Token 带来的结构性噪声。这种机制实现了一种极其精密的网络职能分离:浅层负责对跨域特征进行无死角的全局融合,深层则完全专注于局部时序结构的精准提纯。
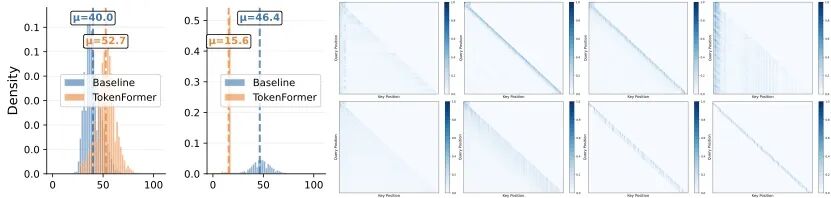
图4-4 Baseline 与 TokenFormer 的逐层注意力模式及感受野分布对比
五、BFTS:打破精度与算力的传统权衡
在这一节中,我们探讨了 BFTS 架构能否打破传统推荐模型在“预测性能”与“计算开销”之间的权衡(Trade-off)。我们的核心假设是:网络浅层需要全局视野来充分融合异构特征,而深层则更受益于局部注意力——这不仅能过滤掉远距离的时序噪声,还能将原本呈平方级的计算复杂度降至接近线性能。
实验结果揭示了注意力层级排布对性能的巨大影响。我们提出的 2F2S(2层全量 + 2层滑动) 架构在所有配置中取得了最佳表现。与全部采用全量注意力(4F)的基线相比,2F2S不仅在 AUC 上提升了 0.85‰,还将计算开销(GFLOPs)大幅削减了 201.0‰。反之,如果将网络顺序颠倒为 2S2F(即在浅层过早地限制了特征交互),AUC 则会断崖式下跌 6.18‰。
这些数据有力地证实了 BFTS 架构带来的双重提升:它既是一个天然的结构正则化器(Structural Regularizer),有效提升了深层表征的纯度;又从根本上降低了模型的推理成本。
窗口尺寸的“逐层收缩”策略
进一步的敏感度分析表明,BFTS 的效能与滑动窗口的大小
实验表明,“逐层收缩(Shrinking)”的窗口配置始终优于“固定大小(Uniform)”的配置。例如,在 2F2S 框架下,采用
综上所述,合理的窗口配置作为一种关键的先验偏置(Inductive Prior),使得 TokenFormer成功兼顾了极高的预测效果与极致的计算效率。
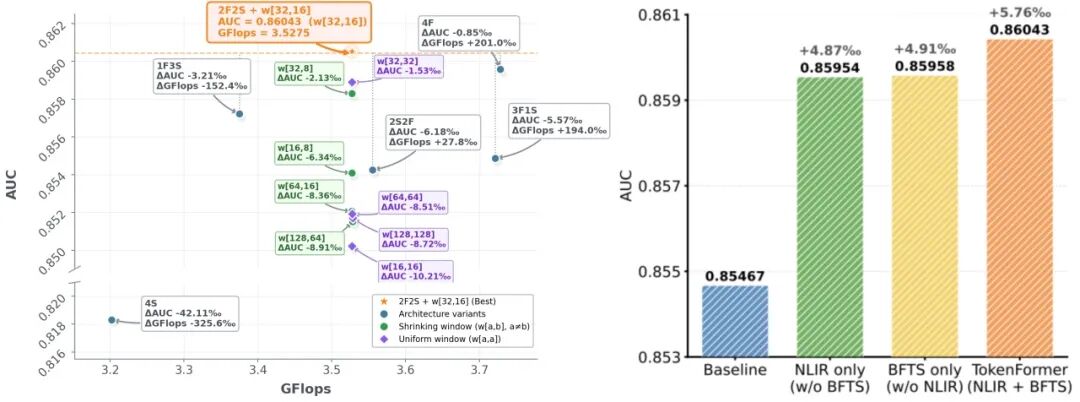
图4-5 BFTS 窗口配置敏感度与 BFTS / NLIR 模块消融实验
六、消融实验:核心组件的独立贡献
为了拆解各个创新组件的独立贡献及其协同效应,我们在 KuaiRand-27k 数据集以及真实工业环境中进行了详细的消融实验。实验结果深刻揭示了非线性交互表示(NLIR)与层次化注意力(BFTS)的有效性。
NLIR 模块的有效性
实验结果表明,在标准 Transformer 中单独引入 NLIR 模块,可使 AUC 提升 4.87‰。这验证了标准线性注意力机制在捕捉高阶特征相关性时存在表达能力不足的局限性。
通过引入显式的非线性乘法交互,NLIR 既增强了特征表示(Embedding)的表达能力,又提高了模型在维度层面的鲁棒性。在对齐稀疏的低维静态特征与稠密的高维序列特征时,该机制有效防止了表征维度的坍塌现象。
BFTS 策略的必要性
在针对滑动窗口注意力(SWA)的对比实验中,若在所有网络层均使用滑动窗口(即 4S 配置),模型的 AUC 会出现 36.35‰ 的大幅下降。分析表明,纯窗口化的架构限制了模型的全局感受野,使其难以捕捉长距离的时序依赖与全局分布模式,进而导致信息碎片化。
相比之下,本文提出的 BFTS 策略(浅层全量融合结合深层局部提纯)有效规避了这一限制。与标准 Transformer 相比,采用 BFTS 策略使 AUC 提升了 4.91‰,这证明了在处理复杂序列时构建层次化感受野的必要性。
工业生产环境的线上消融:为了评估模型在实际复杂业务场景中的应用效果,我们在腾讯广告生产环境中进行了线上测试。线上基准模型(Baseline)为经过大规模业务数据迭代优化的 DLRM 架构。消融轨迹如下:
全量注意力变体:仅采用全量自注意力机制的 TokenFormer 变体表现欠佳,其 AUC 较 DLRM 基线下降了 0.16%。
引入 BFTS:在主干网络中引入 BFTS 机制后,模型性能得到有效改善,AUC 较基线提升了 0.14%。
完整架构 (BFTS + NLIR):在 BFTS 基础上进一步结合 NLIR 模块的完整 TokenFormer 取得了最优表现,其相对线上工业基线的 AUC 实现了 0.22% 的显著提升。
七、模型 Scaling Law 能力
为了评估 TokenFormer 架构的参数容量与扩展潜力,我们通过逐步增加网络深度与隐藏层维度进行了模型缩放(Scaling)分析。
在 KuaiRand-27K 公开数据集上,实验初步验证了缩放定律(Scaling Law):如表4-2所示,随着模型规模从 Tiny 扩展至 Large,其排序精度实现了稳定的提升。然而,当模型进一步扩展至 TokenFormer-L 以上时,性能出现饱和。我们将此现象归因于公开数据集固有的“数据基数瓶颈(Data Cardinality Bottleneck)”——受限于样本规模,高容量模型无法获得充分的正则化,进而导致了轻微的过拟合。
相比之下,在数据规模更为庞大的腾讯广告(Tencent Ads)工业级生产环境中,TokenFormer 展现出了优异的扩展性。随着模型参数量的增加,其性能持续稳步提升,并未出现提前饱和的迹象。
这一对比结果表明,TokenFormer 架构具备较高的表征学习理论上限;在数据充分的大规模工业推荐场景中,该架构能够更有效地发挥其大模型容量的优势。
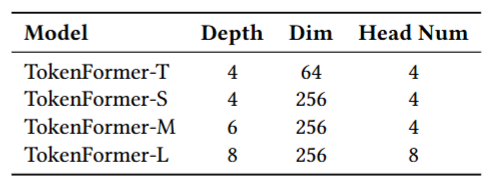
表4-2 模型缩放(Scaling)分析
八、线上 A/B 测试与真实业务收益
为了验证 TokenFormer 在实际业务场景中的有效性,我们将其部署至微信视频号广告系统的信息流推荐核心场景,并开展了为期一个月、涉及 5% 真实流量的线上 A/B 测试。
TokenFormer 架构:相比之下,TokenFormer 取代了之前的解耦建模流程,采用了基于 BFTS 与 NLIR 机制的统一 Token 同构架构。该模型在两年的全量历史数据上进行了从头训练(Train from scratch),随后直接部署上线。
实验结果:在严格的 A/B 测试期间,以核心商业指标 GMV(商品交易总额)作为主要评估标准,TokenFormer 较线上基线系统实现了 4.03% 的显著提升。这一结果不仅验证了 TokenFormer 的离线性能优势可有效转化为线上的实际业务收益,同时也证明:摒弃异构的解耦模块,采用底层统一的同构网络进行推荐建模,在工程实践中具备较高的可行性与实效性。这为下一代大规模工业推荐系统的底座演进提供了一种极具潜力的架构范式。



「腾讯广告技术专题精选」
Highly Efficient 大模型的设计哲学:DeepSeek-V4 技术拆解与推荐算法启示
UniVec 多模态表征大模型:打通全域异构内容,驱动广告推荐精准进化
AI Native研发实践:Spec驱动+AI链路闭环实现智投广告前端






