 高招云直播
高招云直播

了解腾讯营销
腾讯营销(原腾讯广告)是腾讯面向企业的统一商业服务平台,依托腾讯技术实力与全域生态,整合微信、QQ等海量用户场景,构建超十亿用户流量矩阵,连接用户与品牌,并为广告主提供全经营链路数字化营销解决方案,帮助广告主实现数字化经营与生意增长。
这里有
技术:毫秒级处理海量广告请求,算法、大模型、强化学习、AIGC创意生成,工业级难题,真实上线,跑在十亿用户面前;
产品:定义广告主的经营工具,从0到1设计影响真实商业决策的产品体验,每个方案都直接关联真实生意;
营销:用数据和创意重新发明增长,在大规模的商业场景里验证每一个想法。
期待与你一起,探索AI时代下,技术与商业的最新可能。
ABOUTRankUp
5月13日,腾讯发布2026年第一季度财报。当季营收1964.6亿元。
其中,营销服务业务收入同比增长20%至人民币382亿元。
稳健增长的背后,是广告技术的持续迭代。
腾讯Q1财报原文:“营销服务业务二零二六年第一季的收入同比增长20%至人民币382亿元,较二零二五年第四季17%的收入同比增速有所提高。我们升级了AI驱动的广告推荐模型,扩展了微信生态系统内的闭环营销能力,从而带动广告表现提升及广告单价增长。本季大多数主要行业的广告主投放均有所增长,其中互联网服务、电子商务及游戏行业的增长尤为显著。”
过去半年腾讯广告技术团队在底层模型上进行了一次系统性更新——RankUp 高秩表征推荐架构,目前已在微信视频号、公众号&小程序、朋友圈三大流量场景 100% 全量上线。
那么,财报里说的“模型架构升级”,技术上究竟升级了什么?为什么“更复杂”的模型,反而能在效率与表达之间找到平衡?
下面是来自腾讯广告技术团队的一线技术解读:RankUp:从“模型变大”走向“表达变强”|腾讯广告推荐架构的一次范式跃迁,以及目前团队的热招岗位。
期待你的加入,创造更多精彩!

腾讯营销(原腾讯广告)团队多岗位热招中
点击下方岗位名称,一键投递!
青云热招课题
广告推荐模型 Scaling Up(序列和非序列统一建模方向)
面向生成式推荐的强化学习优化技术研究
面向商业化推荐平台的生成式推荐技术研究
基于大模型Agent的腾讯电商广告推荐研究
多模态大模型与强化学习驱动的广告投放Agent
面向商业化推荐的统一多模态生成
面向商业化场景的统一多模态表征大模型技术研究
基于LLM的广告系统实验设计与衡量
机器学习平台技术研究
优化算法在广告推荐场景的应用研究
基于Agentic AI的自主进化广告审核专家Agent构建
大规模语义理解的 agent 数据和知识问答

校招岗位(技术&产品)
算法-多模态方向
算法-推荐算法方向
算法-机器学习方向
技术研究-高性能计算方向
算法-数据科学方向
软件开发-后台开发方向
AI应用开发
产品策划

社招岗位(技术&产品)
大模型深度LTV-算法工程师
大模型广告算法工程师-搜索广告方向
高级广告算法工程师-海外联盟方向
多模态大模型算法工程师
大模型推荐算法负责人
GPU训练工程师
GPU推理加速工程师
广告推荐模型Infra算法工程师/专家
PS 框架研发工程师
行业策略产品-短剧方向
AI投放策略产品经理
阅读行业运营经理
海外广告联盟-预算产品运营
美护行业运营经理


RankUp解读
在大模型技术浪潮的推动下,推荐系统正在快速向更深的网络结构、更高维的表示空间以及更长的用户行为建模演进。行业普遍形成了一种共识:通过不断扩大模型规模,可以持续带来业务指标提升。但在日均千亿级请求的工业实践中,腾讯广告技术团队发现这一传统逻辑正面临严峻挑战:模型体量虽在不断增长,其有效表达能力却并未同步提升,极易陷入“大而不精”的虚胖困境。
针对这一瓶颈,本研究提出了RankUp架构,从底层结构出发重塑表示效率:通过随机特征解耦打破了语义分组带来的信息冗余,从源头上激活了特征的正交性。引入全局 Token 与多 Embedding 映射,在维持网络深度的同时,保障了全局视角的整合与多维语义的表达自由。通过任务级 Token 解耦确保高质量先验信息的顺畅流入,并有效缓解了多任务学习中普遍存在的梯度冲突与表征空间挤占。
目前,RankUp 已全量部署于腾讯营销的CVR 预估任务,其中在微信视频号、微信公众号&小程序、微信朋友圈流量的AB实验的GMV 分别提升了 3.41%、4.81% 和 2.12%。这有力证明了,在 Scaling Law 收益边际减弱的背景下,提升表示效率是工业级推荐系统结构化演进的必然路径。
本文工作已发表至arXiv,论文题目《RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems》。可点击文末「阅读原文」查看。

模型越来越大,但推荐效果真的同步变强了吗?
我们先把视角拉回到一个最朴素的问题——
在推荐系统领域,一个几乎被默认的共识是:更深的网络、更大的参数规模,意味着更强的效果。但在大规模工业实践中,这个逻辑正在被打破。腾讯广告技术团队在日均千亿级请求的真实系统中发现:模型在不断变大,但有效表达能力并没有同步提升。换言之,模型结构变得愈发复杂,却未必变得更“会表达”。
一个关键问题开始浮现:模型变大之后,是否真的带来了同等程度的表达能力提升?
这里的“表达能力”,可以理解为模型刻画信息的精细程度。模型规模的扩张,就像背下了更厚的词典,但真正重要的不是“知道多少词”,在于能否灵活运用这些词汇去精准描述复杂的用户兴趣。如果规模增长无法转化为更丰富的信息组合,那么模型就会陷入一种参数很多,但表达单一的状态。
为了量化这种“模型变大但表达未变强”的现象,本研究引入了一个关键指标:有效秩(Effective Rank)。它衡量的是模型在决策时真正调动的“独立信息维度”。有效秩越高,意味着模型能从更多元、正交的角度理解用户与内容;反之,则意味着信息被挤压在少数维度中,大量参数处于低效运行状态。
01
核心洞察:规模增长背后的“有效表达瓶颈”
研究发现,在主流推荐模型中,随着网络深度与参数规模的增加,输出层的“有效表达能力”并未如预期般单调增长,反而呈现出明显的波动,甚至在深层阶段出现回落。这种现象在多个公开数据集上均表现出一致性。
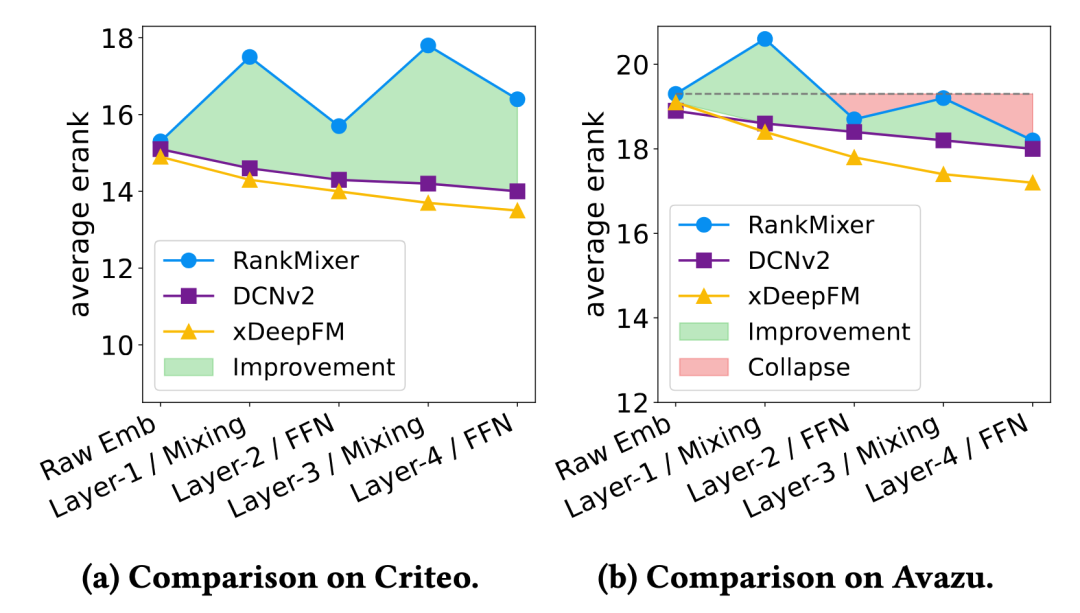
图1-1 基于《Expand More, Shrink Less》实证:在 Criteo 与 Avazu 数据集上,模型加深并未带来有效秩的持续提升
既然有效秩是衡量能力的标尺,那最值得关注的便是“临门一脚”的最终输出层。在推荐排序系统中,最后一层的表征质量直接决定了决策精度的上限。在统一以有效秩作为度量的前提下,对比实验表明:虽然加深网络存在边际效应,但通过优化表示结构,可以显著改善最终表示的有效秩。
这一趋势在腾讯营销的工业实践中也得到了印证:微信视频号精排模型的数据的实验结果显示,RankUp 在输出层实现了稳定的有效秩提升,让模型“更深”的同时也变得“更强”。
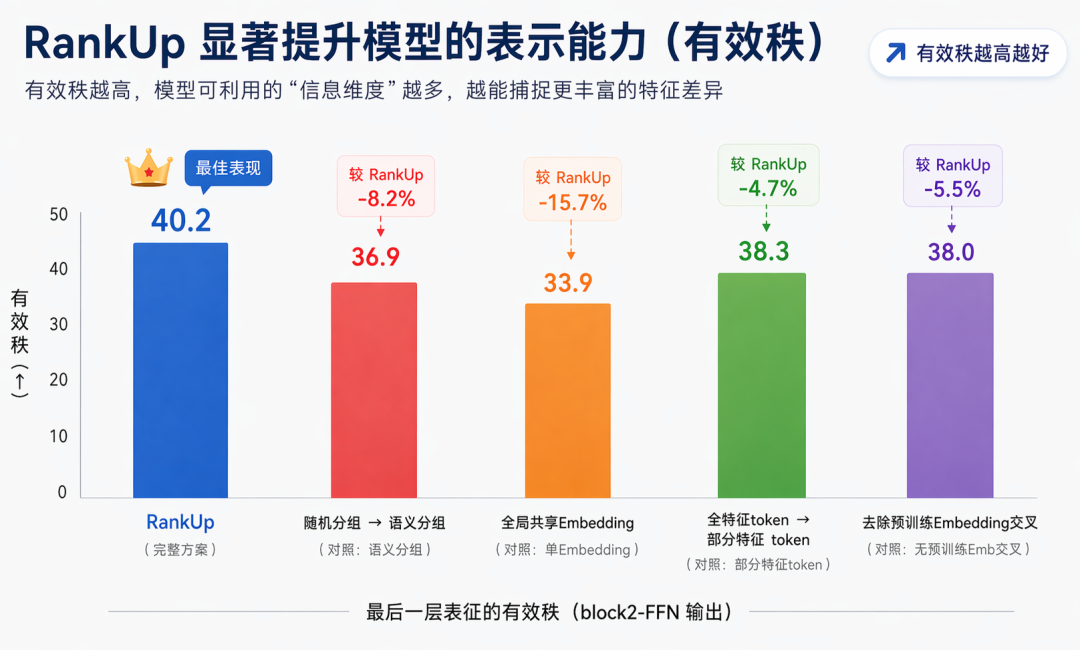
图1-2 腾讯营销视频号精排模型实验结果:RankUp 显著提升模型表示能力(有效秩)
从结构机制来看,这种“表达瓶颈”源于主流模型设计的固有倾向。无论是基于 Token 的交互还是前馈网络(FFN)的非线性映射,都在不同程度上强化了信息的过度融合与压缩。这导致信息在层级传播中不断向少数维度聚拢,引发维度坍缩,进而造成整体表示空间利用率的下降。
在工业场景中,这种“增长容量未转化为充分表达”的脱节现象,会产生两个致命的负面影响:
长尾刻画不足:由于有效表达空间的压缩,模型难以捕捉低频、稀疏用户群体的细腻特征,导致新用户、新广告的推荐效果不佳。
区分度下降:对于高相似度的广告内容,模型因“词穷”而无法辨别其细微差异,限制了排序精度的进一步突破。
简而言之,我们正面临一种“虚胖”的规模化困境:模型的“词典”虽然越修越厚(参数量激增),但其“遣词造句的能力”却在原地踏步甚至退化。如果庞大的参数容量无法转化为更丰富、更独立的表达,那么模型就像一个背下了整本大词典、却只会翻来覆去写简单句的写作者。即便外壳再庞大,它真正的文字底蕴(有效表达能力)依然被限制在极度匮乏的词汇空间里。
02
RankUp 框架:提升表征空间利用率
如果说前半部分讲的是“病灶”,那么 RankUp 给出的,是一份系统性的“药方”——
基于上述洞察,RankUp 提出了一个范式转变:推荐系统的性能瓶颈,正在从“模型容量不足”转向“表示空间利用不足”。如果说此前的优化路径是不断通过“扩修词典”来试图涵盖更多信息,那么 RankUp 则认为:优化重点不应再盲目追求模型规模的简单扩张,而应致力于提升表示空间的信息承载效率与组织方式。
这就好比一位写作者,与其强行背诵更多生僻词,不如精进排版与语法逻辑,让同样的文字载体能承载更深邃、更丰富的意涵。围绕这一目标,RankUp 在多个关键环节进行了系统性设计:
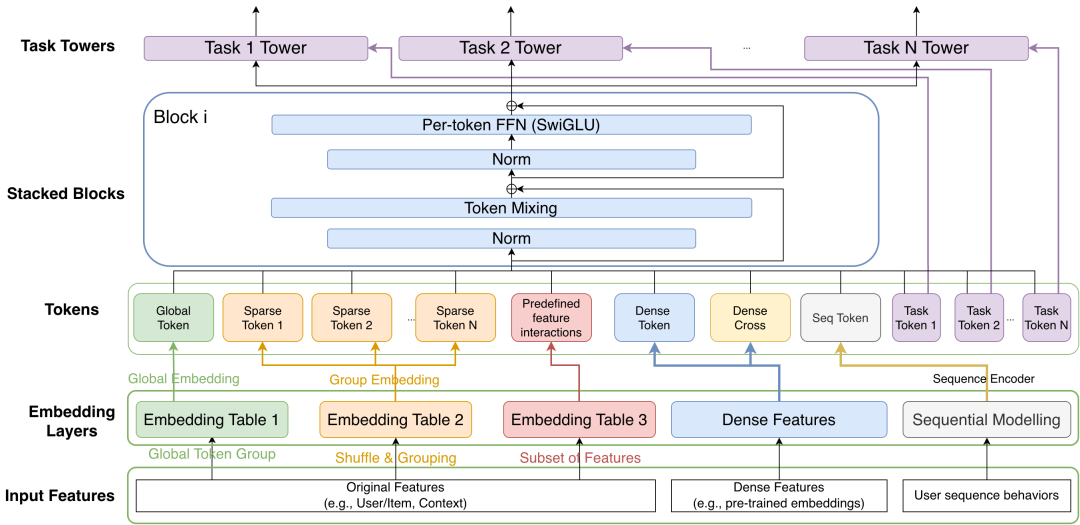
图2-1 RankUp架构设计图示
输入层:随机特征解耦(Randomized Permutation Splitting)
传统做法通常按语义对特征进行分组,例如将“近 7 天点击率”、“近 30 天转化率”等统计类特征放在一起,但这极易导致高度相关的特征在初始阶段就产生信息冗余。
RankUp 通过随机打乱并重新分组,打破了特征间的强耦合,强迫模型从更基础、更正交的原子信息中进行组合,从源头上提升了输入信息的表达潜力。
表示层:多 Embedding 映射 突破“单一特征映射单一 Embedding”的限制
RankUp 突破了“单一特征映射单一 Embedding”的传统限制,通过多个 Embedding 表对同一特征进行多维度描述。这赋予了每个特征“一词多义”的表达自由度,使模型在初始阶段就能从不同侧面捕捉特征的深层内涵,显著增强了表征的丰富性。
结构层:全局 Token 建模
在传统的交互机制中,特征之间往往仅进行“点对点”的局部特征交互,容易导致模型缺乏对整体样本语境的把握。
RankUp 引入了“全局 Token”作为信息的汇聚枢纽,在交互网络中扮演了“全局视角”的角色,避免模型迷失在局部细节中,大幅提升了对复杂场景理解的完整性。
特征融合:预训练表征的显式交互
在利用预训练 Embedding 时,RankUp 不再将其视为静态输入,而是通过逐元素乘法(Element-wise Product)显式地建模用户与物品的交互。这确保了预训练中的“背景知识”能够更有效地转化为排序层所需的“实战洞察”,让沉淀的先验信息更直接地驱动最终决策。
多任务学习:Token 级任务解耦
针对多任务学习中常见的梯度冲突,RankUp 为每个任务分配了独立的专属 Token。这在保留底层参数共享(共用词典)的同时,实现了任务级表征空间的逻辑隔离,如同在同一本书中进行“多线叙事”且互不干扰,有效避免了热门任务对冷门、稀疏任务表征空间的过度挤占。
03
工业级实证:腾讯营销全量100%部署
技术方案最终要回到业务现场。这一节,我们把视角从论文切回腾讯营销的真实流量场景——
在工业级广告系统中,离线 AUC 的提升仅是基础,真正的考验在于复杂生产环境下的转化效率。目前,RankUp 已在腾讯营销系统CVR(转化率)预估任务中完成全量部署。在当前推荐系统已进入“高精度、微百分点优化”的背景下,RankUp 在多个核心流量场景下均实现了极具业务意义的GMV(商品交易总额)增长,以微信流量为例:
GMV = 出价 x 点击率 x 转化率
微信视频号场景:AB实验 GMV提升 3.41%;
微信公众号&小程序场景:AB实验 GMV提升 4.81%;
微信朋友圈场景:AB实验 GMV提升 2.12%。
在当前推荐系统已进入“高精度优化阶段”的背景下,这一量级的提升具有明确的业务意义。
值得关注的是,RankUp 在冷启动场景中的表现尤为突出。如果说普通模型在面对新用户、新内容时如同遇到了从未见过的“生词”,因词汇匮乏而无从下笔;那么 RankUp 凭借其更丰富、更具正交性的表示空间,拥有了极强的“联想与理解能力”。即使在用户行为极度稀疏的情况下,它也能利用其深厚的表征功底,通过对有限信息的深度挖掘,更精准地完成新内容的特征建模。
04
离线实验验证:分析RankUp 的提效机制
针对微信视频号广告精排 pCVR 任务,在真实工业数据集上进行验证。数据规模为日均约2000万样本、1200个稀疏特征、20个月时间跨度。
RankUp 在不同方案下进行了比较,评估其对三个业务任务的影响
下单(Order)、预约(Book)、添加服务(Add Service)。
方案 | 下单(AUC) | 表单预约(AUC) | 添加企业微信(AUC) |
随机特征解耦 | +0.06% | +0.06% | +0.08% |
全局 Token + 多Embedding | +0.21% | +0.18% | +0.13% |
预训练表征的显式交互 | +0.22% | +0.10% | +0.03% |
Token 级任务解耦 | +0.09% | +0.02% | +0.02% |
RankUp 完整版 | +0.41% | +0.23% | +0.25% |
表4-1 RankUp 在不同方案下的AUC比较
每个方案单独上线都有提升,多模块组合后效果进一步增强。其中"全局 Token + 多Embedding"的组合提升最为显著,说明让模型从一开始就"看得更广、记得更多",对最终预测非常有帮助。
随机特征解耦策略
引入互信息(Mutual Information, MI)衡量特征 Token 间的相关性,对比随机分组与语义分组两种特征组织方式。图4-1中展示的是两种分组方式下 MI 的差值分布(随机分组 − 语义分组)。数值越小(颜色越深),表示随机分组下特征 Token 的相关性降低越明显。
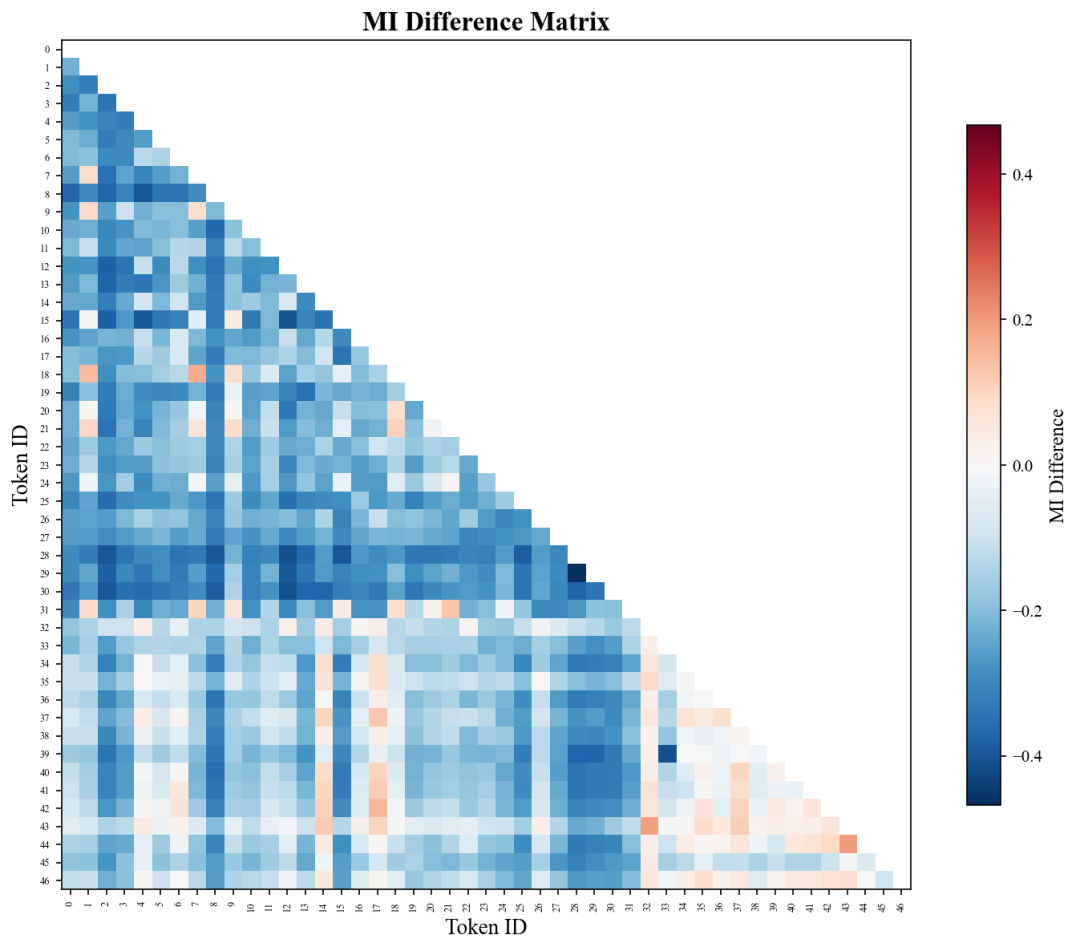
图4-1 两种分组方式下 MI 的差值分布
随机分组情况下,特征 Token 间的互信息整体低于语义分组。说明随机打散策略有效降低了特征间的相关性,使输入信息在表示空间中更加独立,从而提升组合表达的多样性。
各层输出的有效秩变化
对模型各层有效秩进行逐层统计分析,用于观察随深度变化的表达趋势。
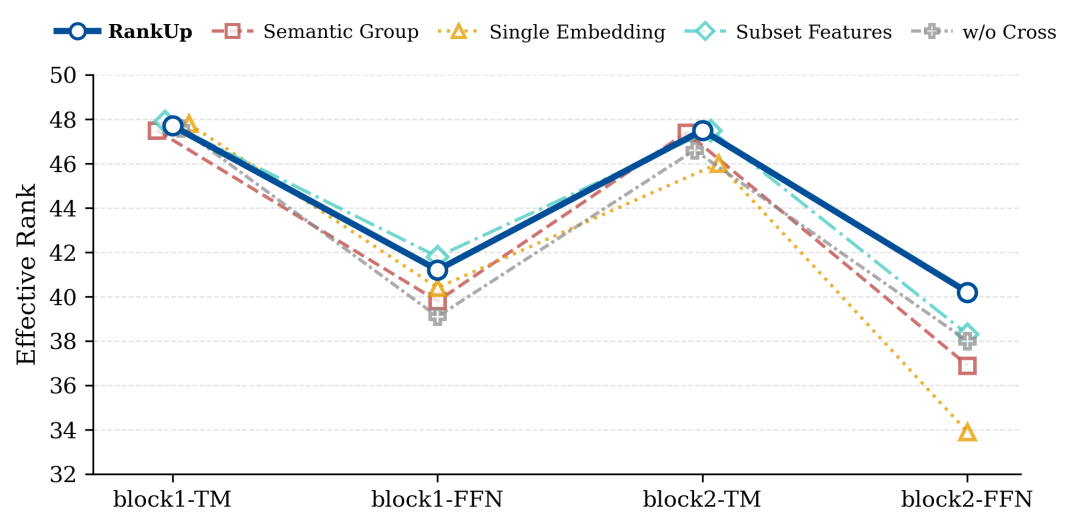
图4-2 各层输出的有效秩变化
随着层数增加,有效秩整体呈下降趋势,下降主要集中在 FFN 堆叠较深的层中。在该现象基础上,各方案对不同阶段的影响如下:
阶段 _ | 主要作用 |
多Embedding映射 | 提升早期表示多样性,防止初始阶段信息压缩 |
全局Token | 稳定深层表示,防止信息随深度增加而丢失 |
预训练表征的显式交互 | 提供丰富的初始化,让模型从第一层就有高质量的起点 |
随机特征解耦 | 降低特征相关性,让信息在各层之间传播更顺畅 |
表4-2 核心设计要素作用总结
05
未来展望
RankUp 所代表的不仅是一种模型改进方案,更标志着推荐系统优化范式正在发生转变:系统优化的核心,正在从依赖“规模扩张”的路径,转向对“表达效率”的重新审视。
在现实工业环境中,随着模型规模持续扩展,系统开始面临算力成本上升、推理延迟增加以及系统复杂度显著提升等多方面压力。这些因素共同限制了模型继续变大所带来的收益,使得模型效能提升的边际收益逐步减弱。更重要的是,这种变化并不只是工程约束的结果,而更像是一种结构性信号:系统正在从“依赖规模堆叠”走向“依赖表达质量”本身。从这个角度看,推荐系统的优化重心正在自然迁移——从“扩大模型规模”,转向“提升表示结构对信息的利用效率”。而 RankUp 的探索,正是在这一转折点上,对“如何更充分使用已有表达空间”这一问题所做的一次回应。
RankUp 是腾讯广告技术团队在"高秩表征"方向上交出的一份阶段性答卷,但远不是这场探索的终点。在大模型与推荐系统持续融合的浪潮中,我们仍在围绕生成式推荐架构、长序列行为建模、统一表征与多模态融合、推理效率与部署成本等前沿方向持续投入。如何让广告系统在“更深的理解”与“更稳的效率”之间走得更远,依然是我们每天在面对的真实问题。
后续,我们会继续分享团队在一线的技术进展与思考,也欢迎你持续关注「腾讯广告技术」,看见更多正在发生的技术进化。



「腾讯广告技术专题精选」
Highly Efficient 大模型的设计哲学:DeepSeek-V4 技术拆解与推荐算法启示
UniVec 多模态表征大模型:打通全域异构内容,驱动广告推荐精准进化





